Présentation Bouffe Front à SFEIR: Comment faire des frontends web performants

Introduction
Bonjour à toutes et à tous. Aujourd’hui, je vais vous présenter quelques diagrammes issus de mon article : “Comment faire des frontends web performants”.
L’article est structuré en trois chapitres :
- Le premier chapitre vise à sensibiliser au fait que le web repose sur une infrastructure physique.
- Le deuxième chapitre aborde les optimisations permettant de réduire l’utilisation des ressources physiques par les pages web.
- Et le troisième chapitre traite des optimisations qui améliorent la performance en réduisant le temps d’attente des utilisateurs.


De la même manière, cette présentation se divise en trois parties :
- La première partie traite de l’empreinte environnementale du web.
- Dans les deuxième et troisième parties, je vous présenterai des diagrammes expliquant certaines optimisations.
J’ai marqué certains sujets comme “à la carte”. Ce sont des sujets pour lesquels j’ai des diagrammes, mais qui ne sont pas inclus dans cette présentation. Nous pourrons les regarder ensemble après, si vous le souhaitez.

Le web repose sur une infrastructure physique.
En arrière-plan, vous pouvez voir des images de mines, d’un data center, d’une déchetterie remplie de téléphones, et d’un champ couvert de panneaux solaires.





Une mesure courante de l’impact environnemental des secteurs économiques est la quantité de gaz à effet de serre émise.
En termes de ce type de pollution, Internet est comparable à l’aviation.
Dans ce diagramme, je détaille la répartition des émissions liées à Internet.
En bleu, je représente les émissions liées à la fabrication du matériel : les appareils utilisateurs, les Data Centers et le réseau.
En jaune, je montre les émissions générées lors de l’utilisation de ce matériel.
Il saute aux yeux que l’empreinte des appareils utilisateurs est supérieure à celle des Data Centers et du réseau réunis. Cela s’explique probablement par le nombre colossal d’appareils utilisés.
On observe également qu’environ la moitié des émissions attribuées aux appareils utilisateurs proviennent de leur fabrication, et l’autre moitié de leur utilisation.
En revanche, les data centers et le réseau émettent 82% de gaz à effet de serre lors de leur utilisation, contre 18% lors de leur fabrication. Une explication possible de cette différence avec les appareils utilisateurs est que les data centers et le réseau appartiennent à des acteurs économiques qui cherchent à rentabiliser leur matériel sur le long terme.


L’impact environnemental du web ne se limite pas à son empreinte carbone.
Il faut une industrie pour produire et alimenter le web, et cette industrie est en compétition pour les ressources avec les autres habitants de la planète, d’où ce diagramme.

Dans cette deuxième version du diagramme, je montre ce qui peut se produire lorsque l’on compte sur davantage de matériel, et sur du matériel plus puissant, pour améliorer la performance du web. On obtient un web qui mobilise une industrie plus importante, et donc laisse moins d’espace à la nature.

Pour conclure cette première partie de la présentation, je vous invite à rejoindre le groupe “Numérique Responsable” de SFEIR.
C’est d’ailleurs grâce à un quiz organisé par ce groupe que j’ai appris que les appareils utilisateur et donc les frontends représentent une part non négligeable de l’empreinte environnementale du web.

Partie 2 : Comment optimiser la performance web en utilisant moins de ressources


Souvent, sur le web, on trouve des sites qui sont lourds non pas à cause de leur contenu, mais parce qu’ils intègrent des éléments superflus.
Par conséquent, avant de chercher des solutions techniques, une première optimisation consiste à n’inclure que ce qui est strictement nécessaire.

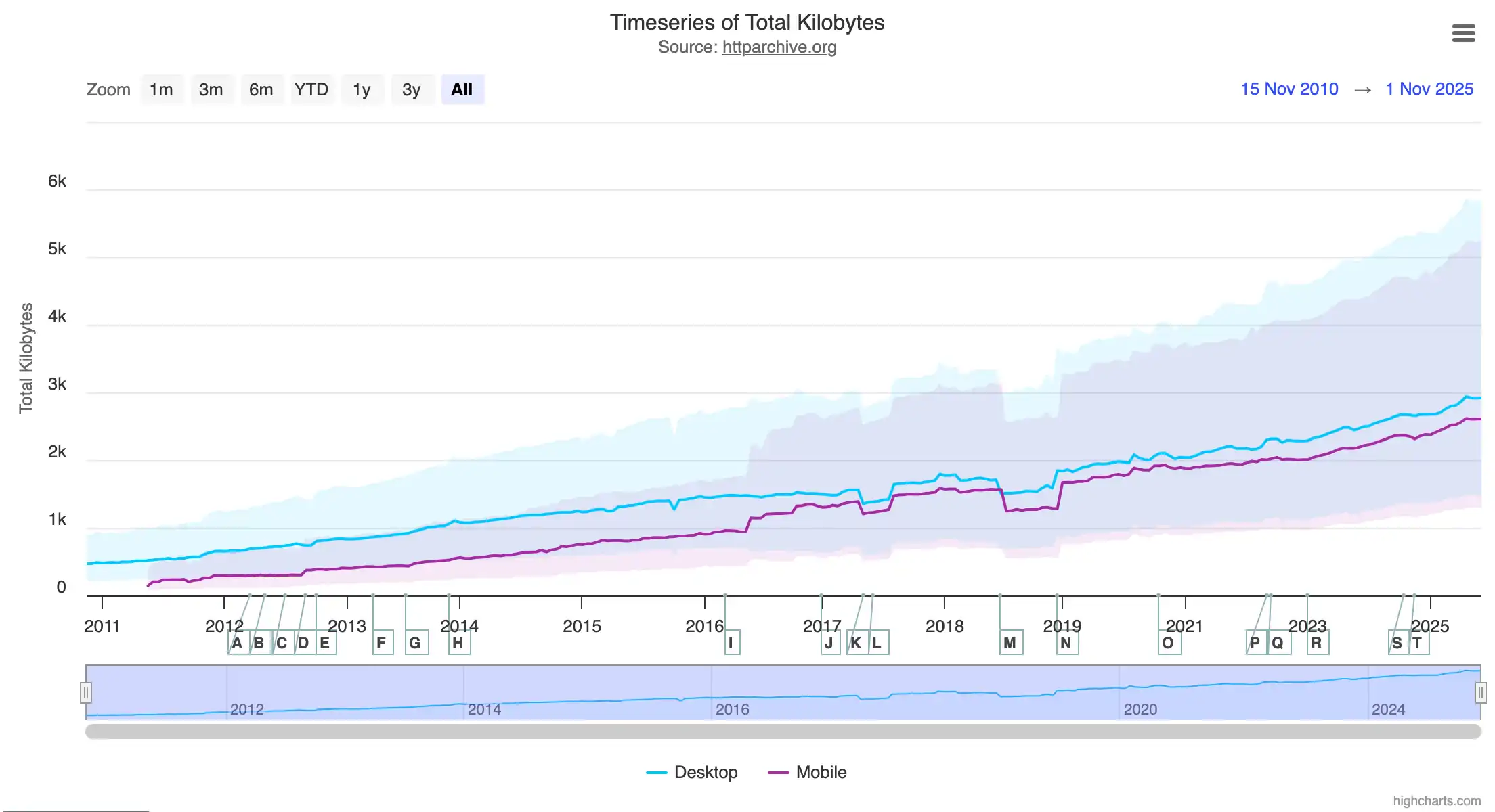
Ce diagramme, tiré du site HTTP Archives, montre que la taille médiane d’une page web était de 0,47 Mo en 2010. Aujourd’hui, elle pèse 2,9 Mo, soit six fois plus.
À titre de comparaison, mon article, riche en diagrammes et qui demande environ 3 heures, voire plus, à lire, ne pèse que 0,18 Mo.

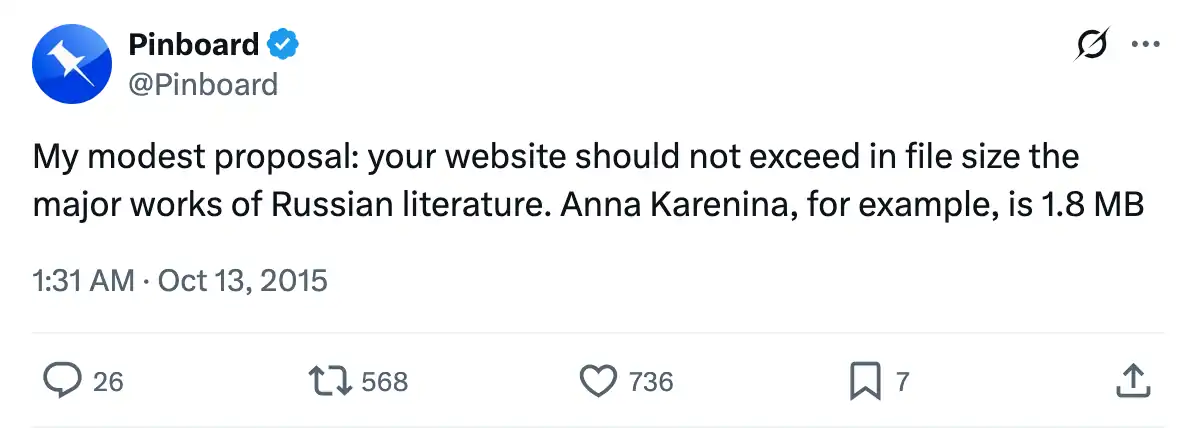
Pour un autre point de comparaison, j’aime citer ce tweet de Pinboard : “La taille de votre page web ne devrait pas dépasser celle d’un roman russe.” Il y cite un roman pesant 1,8 Mo.
J’ai tiré cette citation de la présentation “The Website Obesity Crisis” de 2015, qui est à la fois intéressante et drôle.

Passons maintenant aux approches techniques pour l’optimisation des performances.
La mise en cache
Le cache est une mémoire qui enregistre temporairement une copie des données afin de réduire le temps d’accès lors des requêtes ultérieures.

Cet exemple illustre comment la mise en cache permet d’économiser les ressources du serveur et du réseau.


L’exemple comprend quatre acteurs : le client 1 et son cache, le client 2 et son cache, un cache partagé par tous les clients, et un serveur.
Lorsque le client 1 demande notre page, sa requête arrive au serveur qui génère une réponse. Cette réponse est enregistrée dans le cache partagé.
Lorsque le client 2 demande la même page, le cache partagé lui répond directement, sans solliciter le serveur, réduisant ainsi la charge de ce dernier.

La réponse du serveur est également enregistrée dans le cache de chaque client.
Lorsque les clients demandent la page pour la deuxième fois, celle-ci est servie directement depuis leur cache local, réduisant ainsi la charge du réseau.

Imaginons maintenant une page contenant une partie dynamique qui ne doit pas être mise en cache.
Faut-il pour autant abandonner le cache pour toute la page ? Pas nécessairement.
On peut servir la partie statique séparément de la partie dynamique. Ainsi, la partie statique bénéficie pleinement du cache, et l’on parvient à charger une version à jour de la section dynamique.

C’est ce qui est illustré dans cet exemple avec les trois acteurs : le client et son cache, le cache partagé, et le serveur.


Le client effectue une requête GET pour récupérer la page. Puis, il effectue une deuxième requête pour récupérer la section dynamique.
La partie statique de la page est retournée directement depuis le cache partagé. Quant à la requête pour récupérer la section dynamique, elle atteint le serveur, qui renvoie un header HTTP Cache-Control: no-store pour indiquer au cache de ne pas l’enregistrer.

Lorsque le même client charge à nouveau notre page, la partie statique est récupérée cette fois directement du cache local, et la section dynamique est récupérée depuis le serveur.

Dans l’article, vous trouverez plus d’explications et de diagrammes détaillant le fonctionnement du cache HTTP. Si les titres de cette diapositive vous intéressent, ou si vous n’êtes pas sûr de ce que font les headers HTTP à droite (par exemple, qu’est-ce que ETag ou If-None-Match), je vous invite à consulter l’article.

Avant de terminer la partie sur le cache, j’aimerais évoquer les CDN (ou Content Delivery Networks), qui permettent d’améliorer les performances lorsque les clients d’un site sont répartis dans le monde entier.

Imaginons un serveur situé en France et deux clients : l’un au Québec et l’autre en Afrique du Sud.
La distance physique entre les clients et le serveur augmente les délais de chargement des requêtes.
Cela s’explique par le fait que les données voyagent à une vitesse inférieure à celle de la lumière, qui elle-même met environ 130 millisecondes pour faire le tour de la Terre.

Pour résoudre ce problème, les CDN proposent un réseau de caches décentralisés avec des Points of Presence (PoP) répartis un peu partout dans le monde.
Avec un CDN, lorsqu’un client demande une donnée disponible dans le cache, il reçoit la réponse depuis le PoP le plus proche de lui, réduisant ainsi drastiquement le délai de chargement.
Lorsqu’une requête ne peut pas être satisfaite par le cache, elle doit être transmise jusqu’au serveur, générant un temps de chargement plus élevé (mais cela concerne désormais un volume réduit de requêtes, représenté ici par un trait fin).

Diminuer la taille du code côté client
Maintenant, examinons des optimisations qui réduisent la charge du réseau et des appareils utilisateurs en diminuant la taille du code côté client.

Tout d’abord, il y a les optimisations réalisées par le bundler ou le compilateur. Si vous utilisez un framework, il s’en charge automatiquement pour vous. Cependant, il est important de connaître ces optimisations et de savoir choisir des librairies qui ne les entravent pas. J’en parle dans l’article, mais je n’ai pas de diagramme à vous montrer à ce sujet.
Le deuxième point est l’utilisation de bibliothèques légères.

Je montre ici, à titre d’exemple, deux implémentations de la même application, comprenant chacune 50 Ko de code applicatif.
L’implémentation de gauche utilise des librairies très populaires mais relativement lourdes (React, Next, MUI Date Picker et reCAPTCHA). La taille du bundle de cette implémentation est de 508 Ko.
L’implémentation de droite est réalisée avec des librairies plus légères et pèse moins de 100 Ko, soit moins d’un cinquième de la première.

Une troisième approche pour réduire la taille du code côté client consiste à conserver une partie du code sur le serveur.
Lorsque le client a besoin d’utiliser ce code, il doit effectuer un appel au serveur. Les entrées et les sorties transiteront alors sur le réseau.
Cela implique un compromis entre l’envoi du code et l’envoi des entrées/sorties du code.
Un type de code qui peut bénéficier de cette optimisation est le code responsable du rendering (c’est-à-dire la génération du HTML à partir des données).
Les frameworks nous offrent plusieurs approches possibles : CSR, SSR, Hydratation.
Si l’on se base sur la date de sortie des frameworks qui ont popularisé le CSR, le SSR et l’hydratation, ou même sur leur popularité générale dans la communauté frontend, on pourrait avoir l’impression que le SSR est inférieur au CSR, qui lui-même est inférieur à l’hydratation.
Pour comprendre pourquoi ce n’est pas le cas, rappelons d’abord comment ces approches fonctionnent, à l’aide de diagrammes de séquence.


Commençons par celui du SSR (Server-Side Rendering).
L’utilisateur navigue vers la page. Le client effectue des appels vers le Frontend Server, qui lui-même appelle le backend. Le backend répond avec les données brutes. Le Frontend Server renvoie les fichiers HTML, CSS et JavaScript. Et le client affiche la page à l’écran pour l’utilisateur, puis la rend interactive une fois le script chargé.

Avant de souligner les avantages et les inconvénients du SSR, comparons-le d’abord avec le CSR (Client-Side Rendering).
L’utilisateur navigue vers la page. Le client charge une page vide depuis le Frontend Server. Il télécharge le script de la page. Ce script télécharge ensuite les données depuis le backend. Et enfin, le client génère le HTML à partir des données et affiche la page à l’écran.

En réalité, le rendu de page par CSR présente plusieurs problèmes.
- Premièrement, le serveur envoie une page vide, ce qui peut être interprété comme des “pages blanches” par les moteurs de recherche qui n’exécutent pas le JavaScript. Ce n’est pas idéal pour le référencement de notre page.
- Ensuite, les données sont téléchargées plus tard qu’avec le SSR : on télécharge d’abord le script avant de télécharger les données.
- La page elle-même est affichée plus tardivement.
- Enfin, le client doit télécharger à la fois le code de rendu et le code d’interactivité.
Le point positif du CSR est que le code est déclaratif et simple à écrire et à maintenir.

Maintenant, je reprends le diagramme de séquence pour le SSR :
- On télécharge les données tôt depuis le backend.
- On affiche la page tôt au client.
- On ne télécharge que le code nécessaire à l’interactivité, car le rendu HTML est effectué côté serveur.
Le revers de la médaille est que le code responsable de la gestion de l’interactivité est impératif, et donc potentiellement plus difficile à écrire et à maintenir.

C’est pourquoi des approches de rendu hybrides, combinant SSR et CSR, ont été développées. La plus répandue de ces approches est l’hydratation.
Le même code JavaScript, déclaratif, peut s’exécuter côté serveur et côté client. Au chargement de la page côté serveur, le Frontend Server génère le HTML. Côté client, le framework se charge d’attacher les event hundlers à ce HTML pour le rendre interactif.


Ainsi, avec l’hydratation, comme avec le SSR pure:
- on charge les données tôt,
- on n’envoie pas une page vide,
- et on affiche la page rapidement à l’écran.
On combine donc les bénéfices du CSR et du SSR : un code déclaratif et de bonnes performances.
Mais ce n’est pas toute l’histoire.

Comparons les données envoyées aux clients avec SSR, CSR et hydratation.
Nous allons examiner ce qui doit être envoyé en termes de :
- Code JavaScript côté client
- Données brutes (par exemple, au format JSON)
- Code HTML
J’utilise comme exemple une page avec deux templates HTML. Le template 1 est instancié une fois, et le template 2 est instancié trois fois, avec à chaque fois des données différentes.
Avec le SSR, nous envoyons les templates et les données sous forme de HTML. On peut voir que le template 2 est répété trois fois dans le HTML.
Nous envoyons également le code nécessaire pour rendre les templates 1 et 2 interactifs.


Avec le CSR, nous envoyons quasiment rien dans le HTML. Nous envoyons les données brutes au client. Et nous envoyons le code JavaScript pour le rendu et pour l’interactivité des deux templates.
On remarque que le template 2 n’est pas envoyé plusieurs fois au client, comme avec le SSR.

Avec l’hydratation, nous envoyons le code des deux templates et de leur interactivité, comme avec le CSR. En plus, il faut envoyer le code du framework implémentant l’hydratation. Il faut envoyer les données sous forme brute, comme avec le CSR. Nous envoyons les templates et les données une deuxième fois dans le HTML.
On remarque également que le template 2 est répété trois fois, comme avec le SSR. Et cerise sur le gâteau, nous envoyons des métadonnées pour supporter l’hydratation.

On constate qu’il ne faut pas opter pour l’hydratation sans réfléchir. Parfois, le SSR ou le CSR offrent de meilleures performances.
Je parle dans l’article de l’hydratation partielle, qui tente de remédier à ces problèmes. De plus, l’hydratation n’est pas la seule façon d’hybrider SSR et CSR.
Partie 3 : Faire de l’ordonnancement intéligent
Passons maintenant à la partie 3 de la présentation : comment optimiser la performance, non pas nécessairement en réduisant l’utilisation des ressources, mais en réduisant le temps d’attente des utilisateurs grâce à un ordonnancement intelligent.
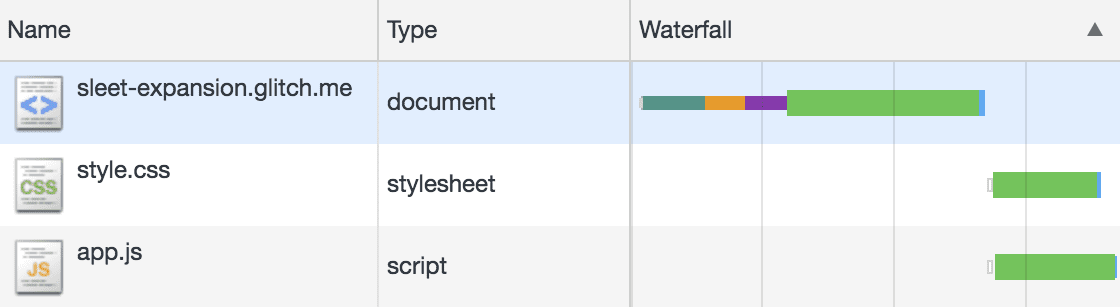

Dans cette partie, nous allons voir beaucoup de diagrammes de Gantt, comme celui-ci.
Dans le web, on appelle ces diagrammes des “waterfall diagrams”, et on peut les visualiser dans l’onglet “Réseau” des outils de développement du navigateur.
Ceci dit, les diagrammes de mon article sont générés par simulation. Ils incluent non seulement les tâches côté client, mais aussi celles côté serveur. Et grâce au code de simulation, je peux contrôler les paramètres réseau de manière reproductible.
Ne pas bloquer le thread principal
La première optimisation, ou plutôt l’erreur à éviter, c’est qu’il ne faut pas bloquer le thread principal de la page web.

Dans cet exemple, l’utilisateur effectue deux clics : un à l’instant zéro, puis un second à 500 millisecondes.
Suite au premier clic, le navigateur exécute le code “handle click #1”. Ce code se termine rapidement, mais il lance une tâche longue qui prend beaucoup de temps à exécuter.
Lorsque l’utilisateur effectue son deuxième clic, le thread principal est occupé par cette tâche longue. Seulement après la fin de cette tâche, le navigateur peut traiter le deuxième clic.
Quand le code “handle click 2” se termine, le navigateur recalcule la layout de la page et affiche le résultat à l’écran à l’instant 1000 millisecondes.

Une façon de contourner ce problème est de diviser la tâche longue en plusieurs tâches plus courtes qui libèrent périodiquement le thread principal, permettant au navigateur de traiter les événements générés par l’utilisateur.
Dans cet exemple, lorsque l’utilisateur clique une deuxième fois, le thread principal est bloqué, mais pas très longtemps.
Après moins de 100 millisecondes, le navigateur exécute le code “handle click 2”, refait la layout, et affiche le résultat à l’instant 720 millisecondes.

Une autre façon d’aborder ce problème est d’exécuter la tâche longue en dehors du thread principal. C’est possible grâce à l’API Web Workers.
Ainsi, lorsque l’utilisateur clique une deuxième fois, le navigateur traite directement cet événement. La page est donc affichée à l’instant 650 millisecondes.

Le streaming
Passons maintenant à des optimisations plus intéressantes qui impliquent le client, le serveur et le réseau : Commençons par le streaming.
Voici le diagramme de Gantt du chargement d’une page web contenant un fichier style.css et un script.js.
L’objectif est que le navigateur puisse calculer la mise en page (la tâche en bleu) le plus tôt possible pour afficher la page à l’écran.

Zoom sur cette partie du diagramme pour expliquer le principe.
J’affiche dans ce diagramme les tâches côté client et côté serveur. Pour le fichier page.html, j’affiche deux lignes : une pour le chargement de la page côté client, et une autre pour la génération de la page côté serveur.
Le client envoie une requête pour télécharger la page. Avant que la requête n’atteigne le serveur, il faut d’abord attendre que le premier octet de la requête voyage physiquement entre le client et le serveur (il s’agit de la latence réseau). Puis, il faut attendre le temps de transmission du contenu de la requête HTTP.
Une fois que le serveur a reçu la requête, il génère le head et le body de la page. Ensuite, il les envoie au client.
Après un délai de latence réseau, le client reçoit le contenu du head de la page, puis le contenu de son body.

Maintenant, regardons ce qui se passe avec le streaming, qui est simplement l’envoi progressif des données.
Le client envoie une requête pour télécharger la page. Le serveur génère le head de la page et l’envoie au client. En parallèle, le serveur génère le body de la page. Une fois prêt, il le transmet au client.

Revenons à notre diagramme pour le chargement d’une page sans streaming.
Le client demande le fichier page.html. Le serveur prend quelques millisecondes pour générer le head de la page. Puis, il lui faut 250 millisecondes pour générer le body. Une fois que le head et le body sont prêts, le serveur envoie la réponse au client.
Dès que le client reçoit le head, et sans attendre de recevoir le body de la page, il peut voir les balises HTML pour le style et le script. Il envoie donc deux requêtes au serveur.
Le serveur répond rapidement à ces requêtes de fichiers statiques.
Une fois les deux fichiers style et script téléchargés et interprétés, le navigateur calcule la layout de la page et affiche la page à l’écran à l’instant t=1000 ms.
On remarque que le client ne peut commencer à télécharger les fichiers style et script qu’après la génération du body de la page côté serveur.

Regardons maintenant ce qui se passe lorsque l’on utilise le streaming.
Le client envoie une requête pour la page HTML. Le serveur génère le head, puis en parallèle, il commence à générer le body et envoie le head au client. Dès que le client a téléchargé le head, il envoie les requêtes pour télécharger le style et le script. Le serveur répond à ces requêtes et continue de générer le body. Une fois le body généré et transmis au client, et une fois que le client a fini d’interpréter le style et le script, il calcule la layout et affiche la page à l’instant T = 785 ms, soit plus de 200 millisecondes plus tôt qu’avec la version sans streaming.
Le streaming a permis au client de télécharger les fichiers style et script peu de temps après la génération du head de la page côté serveur. Il les télécharge en parallèle avec la génération du body côté serveur.


Examinons maintenant une application plus avancée du streaming : le “out-of-order streaming”, implémenté par MarkoJS en 2014, et plus récemment par des frameworks plus populaires comme Next.js fin 2022.
Dans cet exemple, nous avons une page qui charge un fichier style.css et un script.js. Côté serveur, pour générer cette page, le serveur utilise trois threads pour générer trois sections de la page en parallèle.
Cette implémentation fait du “in-order streaming”, c’est-à-dire que la section 1 doit être délivrée au client avant la section 2, et ainsi de suite.
Le client envoie la requête pour la page.html. Le serveur génère le head, puis en parallèle, il envoie le head au client et commence à générer les trois sections de la page.
Le client télécharge et interprète les fichiers style et script.js. On peut voir que le thread 2 a fini de générer la section 2. Mais comme on stream la page dans l’ordre, et comme la section 1 n’est pas encore prête, la section 2 doit attendre.
Du coup, le client affiche une page vide à l’écran. Une fois que la section 1 est générée, le serveur stream les trois sections de la page au client, et le client les affiche au fur et à mesure qu’elles arrivent.


Regardons maintenant comment se charge la même page si l’on utilise le “out-of-order streaming”.
Le client fait la requête pour page.html. Le serveur génère le head. En parallèle, il stream le head au client et commence à générer les trois sections de la page. Le client télécharge et interprète les fichiers style et script.js. On voit qu’une fois que la section 2 est générée côté serveur, elle est streamée au client. Du coup, le navigateur dispose déjà de la section 2 et peut l’afficher à l’écran. Cela arrive à l’instant 770 ms, soit 400 millisecondes plus tôt que dans l’exemple précédent. Puis, au fur et à mesure que les autres sections sont générées et transmises au client, elles sont affichées par ce dernier.


Le Preloading
Passons maintenant à l’optimisation suivante : le “preloading”, qui permet d’éliminer encore plus de temps d’attente inutile.
Pour le preloading, j’ai créé cet exemple avec une page HTML qui charge un fichier style.css, lequel importe à son tour un autre fichier style-dependency.css.

Ce diagramme montre le chargement de cette page si l’on n’utilise pas de preloading. Le client demande la page HTML. Une différence avec les diagrammes précédents est que, pour cet exemple, le serveur prend 250 millisecondes pour déterminer le code de statut de la page (par exemple, s’il doit répondre avec un statut 200 OK ou 404 Not Found).
Une fois le code de statut déterminé, le serveur génère le head de la page et envoie, en parallèle, le code de statut au client.
Une fois le head généré et servi au client, celui-ci voit la balise du style et lance le téléchargement de ce fichier.
Une fois style.css téléchargé, le client voit l’instruction import et lance le téléchargement du fichier style-dependency.css.
Une fois les deux fichiers téléchargés et interprétés, le client calcule la mise en page et affiche la page à l’écran.
On observe donc deux dépendances :
- Le
style.cssne peut être téléchargé qu’après la génération et la réception du head côté client. - Le fichier
style-dependency.cssne peut être téléchargé qu’après la réception du fichierstyle.csscôté client.


—
Voici la même page, mais avec une balise <link rel="preload"> pour précharger le fichier style-dependency.css. Une balise <link rel="preload"> permet de charger une ressource sans l’insérer directement dans la page. Ainsi, lorsqu’on a réellement besoin de la ressource, elle sera déjà chargée ou en cours de chargement.

Voici le diagramme du chargement de la page avec cette balise de preload. Nous ne le détaillerons pas entièrement. La partie intéressante est que dès que le client a reçu le head de la page, il peut télécharger les deux fichiers style.css et style-dependency.css.


En fait, on peut faire mieux : on peut effectuer du preloading avec des en-têtes HTTP. Ces en-têtes ressemblent à ceci. Ils peuvent être envoyés avant même que le head de la page ne soit généré.



De plus, depuis bientôt deux ans, tous les navigateurs modernes (sauf Safari) supportent l’envoi d’en-têtes de preloading, même avant de déterminer le code de statut de la page, grâce à un code de statut spécial : le 103 Early Hints.

Avec cette optimisation, lorsque le serveur reçoit la requête, il répond instantanément avec un code de statut 103 Early Hints et des headers de preloading, permettant ainsi au client de commencer à télécharger les fichiers style.css et style-dependency.css avant même que le code de statut de la page ne soit déterminé.


Pour un deuxième exemple de preloading, voyons comment accélérer le chargement initial d’une Single Page Application (SPA) qui utilise le CSR.
Cette page charge un fichier style, un script et un fichier data.json. Le serveur répond très rapidement avec une page vide, car nous allons effectuer un rendu côté client (CSR).
Sans preloading, le client reçoit la page et lance le chargement du style et du script. Lorsque le script s’exécute, il effectue une requête pour télécharger le fichier data.json, et ce n’est qu’après que le client a reçu ce fichier qu’il peut afficher le contenu de la page.


Regardons maintenant ce même exemple, mais avec l’utilisation d’une balise <link rel="preload"> pour charger le fichier data.json.
Lorsque le client reçoit la page HTML, il télécharge immédiatement les trois ressources de la page. Lorsque le script s’exécute, il essaie de charger data.json, mais le trouve déjà dans le cache. Par conséquent, on évite un aller-retour vers le serveur et on affiche le contenu de la page rapidement.


Je vous renvoie à l’article pour d’autres diagrammes, exemples et cas de figure de preloading.
Conclusion
Pour conclure :
- Dans la première partie de la présentation, nous avons vu comment le Web est un système physique.
- Dans la deuxième partie, nous avons abordé des optimisations permettant de réduire l’utilisation des ressources.
- Dans la troisième partie, nous avons examiné des optimisations visant à éliminer les temps d’attente inutiles.

Il reste encore beaucoup de matière à explorer dans l’article, qui cite 117 liens externes et contient 55 diagrammes au total.

Je vous remercie de votre attention.
